cuda cuda_使用cuda并行加速实现之reduction
”cuda 并行加速 reduction“ 的搜索结果
为了做这样一个累加和的加速,有两种简单的实现方法,分别是 Redece 进行归约(二分),或者是用 Scan 通过控制步长进行扫描求和。 Reduce 如上图所示为了并行执行累加,我们要构造出一些线程,每个线程并行工作,...
CUDA是SIMT模型,只用写一个程序,其中就包含了CPU部分和GPU并行部分的代码,那么就需要指明哪些是CPU(一般称为HOST),哪些是在GPU上运行(一般称为device)。对于变量,也就是数据,我们需要存放在GPU上,以便GPU端...
通过使用原子添加操作来更新并行计算环境中的共享内存位置,开发人员可以确保他们的计算结果是准确和一致的,即使是在多个线程访问和更新相同的数据时。例如,设定变量 real(kind=RK), intent(inout) :: acc_wk(3,...
CUDA并行计算的高效策略 1.最大化计算强度(高效公式) 包括最大化计算量和最小化每个线程的内存读取速度。 2.合并全局内存 其中连续合并>间隔合并>随机合并 3.应该避免线程发散(同一线程块中的线程执行不同...
并行归约(Reduction)是一种并行算法,对于符合结合律的二元操作符,将输入的数组划分为更小的数据库,每个线程计算1个数据块的部分结果,最后把所有部分结果再计算,得出最终结果。二元操作符可以是求和、取最大、...

实验2: Data Parallel Reduction 适合CUDA初学者练习
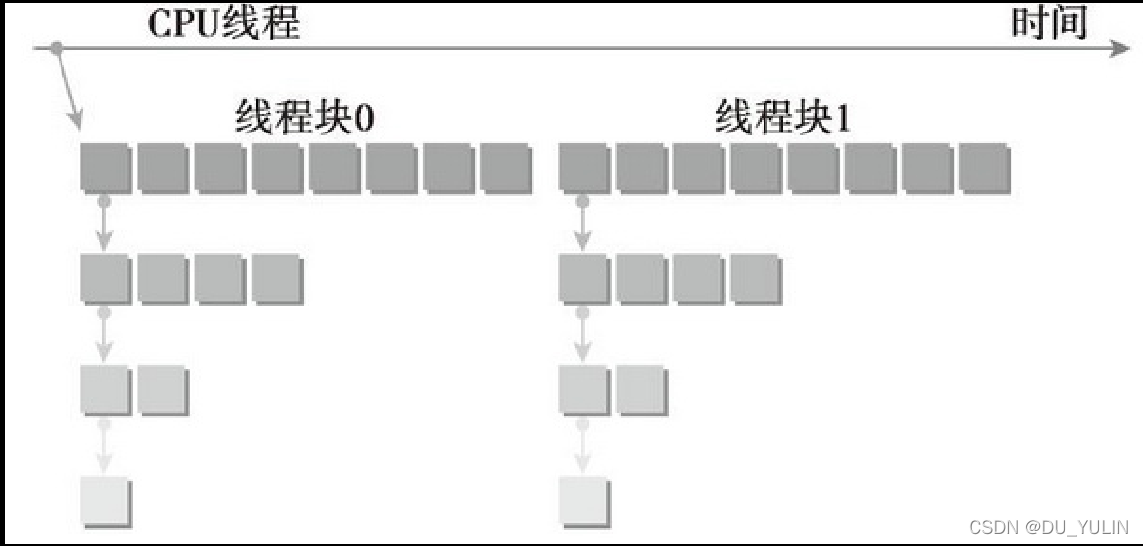
Reduction并行分析: 每个线程是基于一个树状的访问模型,从上至下,上一层读取数据相加得到下一层的数据.不停的迭代,直到访问完所有的数据. 利用这么多的线程块(thread block)我们需要做的事情如下: 1. ...
Python基于pyCUDA实现GPU加速并行计算功能入门教程发布时间:2020-10-02 00:42:11来源:脚本之家阅读:116作者:hitrjj本文实例讲述了Python基于pyCUDA实现GPU加速并行计算功能。分享给大家供大家参考,具体如下:...
线程和并发C++:创建多线程求数据平均值方法:使用几何分解,使用functor创建线程,使用functor和资源获取即初始化(RAII)原则创建管理线程。避免线程间争用条件:使用mutex求解数值平均值。共享资源和程序终止方式...
CUDA是Nvidia GPU上的并行计算架构,使用该架构可以对GPU进行高效运算,以加速Python程序的运行。 本文实例讲述了Python基于pyCUDA实现GPU加速并行计算功能。分享给大家供大家参考,具体如下:
GPU并行加速编程 opencl CUDA 核函数 OpenCL(全称为Open Computing Langugae,开放运算语言)是第一个面向异构系统(此系统中可由CPU,GPU或其它类型的处理器架构组成)的并行编程的开放式标准。 它是跨平台的。 OpenCL...
我们知道,GPU擅长做并行计算,像element-wise操作。GEMM, Conv这种不仅结果张量中元素的计算相互不依赖,而且输入数据还会被反复利用的更能体现GPU的优势。但AI模型计算或者HPC中还有一类操作由于元素间有数据依赖...

CUDA架构是围绕一个流式多处理器的可扩展阵列搭建的。Fermi SM的关键组件:CUDA核心共享内存/一级缓存寄存器文件加载/存储单元特殊功能单元线程束调度器。每个SM都能支持数百个线程并发执行,每个GPU通常有多个SM,...
CUDA并行算法系列之规约前言规约是一类并行算法,对传入的N个数据,使用一个二元的符合结合律的操作符⊕,生成1个结果。这类操作包括取最小、取最大、求和、平方和、逻辑与/或、向量点积。规约也是其他高级算法中...
注:本人代码是对长度为1024的数组排序; block数量为1,threads数量为256 p135页代码应改为: __device__ void merge_array(u32 *src,u32 *dest,u32 num_... u32 reduction_shift=3; u32 reduction_size=8; u32
本文实例讲述了Python基于pyCUDA实现GPU加速并行计算功能。,具体如下:Nvidia的CUDA 架构为我们提供了一种便捷的方式来直接操纵GPU 并进行编程,但是基于 C语言的CUDA实现较为复杂,开发周期较长。而python 作为...
CUDA C并行性衡量指标介绍二、案例介绍1. 案例说明2. 案例实现3. 结果分析总结参考资料 前言 CUDA编程,就是利用GPU设备的并行计算能力实现程序的高速执行。CUDA内核函数关于网格(Grid)和模块(Block)大小的...
归约(redution)是一类并行算法,对传入的O(N)个输入数据,使用一个二元的复合结合律的操作符,生成O(1)的结果。这类操作包括取最小、最大、求和、平方求和、逻辑与、逻辑或、向量点积。归约也是其他高级运算中要用...
2、所有的数据块并行求部分和 3、对所有的部分和进行求和得到结果 接下来介绍各种并行规约的方法。 相邻配对-1 每一个block负责计算出一个部分和。 首先有两个全局数组,g_idata和g_odata,分别存放...
此文实例介绍了Python基于pyCUDA实现GPU加速并行计算功能。推荐给大伙学习一下,内容如下:Nvidia的CUDA 架构为我们提供了一种便捷的方式来直接操纵GPU 并进行编程,但是基于 C语言的CUDA实现较为复杂,开发周期较长...
本文主要介绍如何使用CUDA并行计算框架编程实现机器学习中的Kmeans算法,Kmeans算法的详细介绍在这里,本文重点在并行实现的过程。
CUDA C编程权威指南》以及 CUDA官方文档CUDA编程:基础与实践 樊哲勇文章、讲解视频同步更新公众《AI知识物语》,B站:出门吃三碗饭。
CUDA:使用流进行并发执行的实例
#include "../common/common.h" #include <cuda_runtime.h> #include <stdio.h> /* ... * parallel reduction in CUDA. For this example, the sum operation is used. A * variety o.
并行规约是在CUDA中广泛使用的一种技术,用于对数组或集合进行归约(reduction)操作,从而高效地计算出一个汇总结果。 ## 1.2 并行规约在高性能计算中的重要性 在高性能计算中,数据集合的归约操作非常常见,例如...
Parallel Reduction是NVIDIA-CUDA自带的例子,也几乎是所有CUDA学习者的的必看算法。在这个算法的优化中,Mark Harris为我们实现了7种不同的优化版本,将Bandwidth几乎提高到了峰值。相信我们通过仔细研读这个过程,...
推荐文章
- Android 编译so文件 MP4V2_android下编译mp4v2-程序员宅基地
- 通讯录Contact_02_contact文件内容-程序员宅基地
- Qt笔记(四十二)之QZXing的编译 配置 使用_qzxingfilterrunnable error:-程序员宅基地
- 关于画图软件Dia打开程序始终为英文界面的问题-程序员宅基地
- OpenCV从入门到精通实战(二)——文档OCR识别(tesseract)-程序员宅基地
- 详解avcodec_receive_packet 11_avcodec_receive_packet eagain-程序员宅基地
- OpenGL SuperBible 7th源码编译记录_superbible7-media github-程序员宅基地
- Wireshark简单使用-程序员宅基地
- MXNet 粗糙的使用指南_iou loss mxnet-程序员宅基地
- iOS对ipa包进行代码混淆《二》 ---代码混淆_ipa包混淆-程序员宅基地